This is the first in a small series of blog posts about Kubernetes Ingress Controllers. While later posts will deal with some specific implementations and their respective details, here I first start out by introducing the general picture and the basic concepts.
All contents presented here will be covered in more detail as part of the Novatec training “Docker und Kubernetes in der Praxis”.
Kubernetes Ingress
Kubernetes Ingress has finally been declared “stable”, i.e. having a well-defined API making it fully available for general use, with the release of Kubernetes v1.19 in August 2020. To summarize the upstream documentation, Ingress exposes routes from outside the cluster to services within the cluster, providing
- traffic control via rules
- name-based virtual hosting
- route-based virtual hosting (fanout)
- TLS/SSL termination / SSL offloading
- load balancing
And an Ingress Controller is the component that actually fulfills the Ingress.
What does that mean?
So, why would I even need anything like that? After all, I can easily expose Kubernetes workloads to the internet using a LoadBalancer Service with an external IP address.
Well, I can, but there are some severe limitations involved with that: while exposing a workload directly like this is really easy, and Kubernetes readily allows for balancing incoming connections over a number of worker containers, each such workload will stand alone on its own, having to individually implement additional features like encrypting traffic or access control by themselves, and each workload will thus not be easily integrated into a common setup.
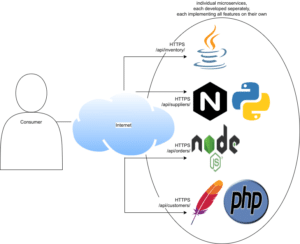
Let’s imagine having a polyglot stack with an application implemented in several microservices, each written in a different language and thus each with a different type of server, and the need to offload traffic encryption or access control to a central interface, as opposed to implementing this individually in each microservice or server, becomes great indeed. And let’s imagine that these microservices each provide a specific subpart of a common API, e.g. one serving /api/customers/ and another one serving /api/orders/, I wouldn’t want to expose them on differing IP address but rather would like to see them consolidated below my.domain.io/api/ in order to comply with the Same-origin policy.
Such a stack might be visualized like this:
So what would I need instead?
I’m going to focus on a subset on the challenge first: consolidating separate microservices under a common IP address.Sample services
Let’s simulate two sample microservices using HashiCorp‘s http-echo container, making orders and customers endpoints each available in my Kubernetes cluster under their name and on TCP port 5678, and each just echoing what part they are supposed to handle:apiVersion: apps/v1
kind: Deployment
metadata:
name: customers
spec:
replicas: 1
selector:
matchLabels:
app: customers
template:
metadata:
labels:
app: customers
spec:
containers:
- name: customers
image: hashicorp/http-echo
args:
- -text="customers handled here"
---
apiVersion: v1
kind: Service
metadata:
labels:
app: customers
name: customers
spec:
ports:
- port: 5678
selector:
app: customers
and likewise
apiVersion: apps/v1
kind: Deployment
metadata:
name: orders
spec:
replicas: 1
selector:
matchLabels:
app: orders
template:
metadata:
labels:
app: orders
spec:
containers:
- name: orders
image: hashicorp/http-echo
args:
- -text="orders handled here"
---
apiVersion: v1
kind: Service
metadata:
labels:
app: orders
name: orders
spec:
ports:
- port: 5678
selector:
app: orders
No Service type has been specified, so these services will be created as ClusterIP services, making their workload only available from within the cluster.
Consolidate into common setup
For now I’d like to consolidate my various microservice subparts as mentioned above into a common setup. This can easily be achieved “manually” using a centralized entry point in form of a Reverse Proxy implemented using Nginx:apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-config
data:
nginx.conf: |-
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
keepalive_timeout 65;
server {
listen 80;
location /api/customers/ {
proxy_pass http://customers:5678; # service name and port of our Kubernetes service
}
location /api/orders/ {
proxy_pass http://orders:5678; # service name and port of our Kubernetes service
}
}
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: reverseproxy
spec:
replicas: 1
selector:
matchLabels:
app: reverseproxy
template:
metadata:
labels:
app: reverseproxy
spec:
containers:
- image: nginx:alpine
name: reverseproxy
ports:
- containerPort: 80
volumeMounts:
- name: nginx-reverseproxy-config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
- name: nginx-reverseproxy-config
configMap:
name: nginx-config
---
apiVersion: v1
kind: Service
metadata:
labels:
app: reverseproxy
name: reverseproxy
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: reverseproxy
So, the (rather minimal) ConfigMap contents will be placed at /etc/nginx/nginx.conf in the container for Nginx to consume accordingly, configuring our Reverse Proxy as desired: each endpoint access will be proxied to the respective internal service. And this Reverse Proxy by itself will be made available for external access using a LoadBalancer service.
Output
Once applied, kubectl get all might show like this:NAME READY STATUS RESTARTS AGE pod/customers-b59bf9968-vlggf 1/1 Running 0 14m pod/orders-66b48ff4bb-9t96k 1/1 Running 0 14m pod/reverseproxy-7977b6bd7f-9wprr 1/1 Running 0 14m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/customers ClusterIP 10.97.75.61 <none> 5678/TCP 14m service/orders ClusterIP 10.99.68.38 <none> 5678/TCP 14m service/reverseproxy LoadBalancer 10.111.121.237 172.18.255.1 80:30531/TCP 14m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/customers 1/1 1 1 14m deployment.apps/orders 1/1 1 1 14m deployment.apps/reverseproxy 1/1 1 1 14m NAME DESIRED CURRENT READY AGE replicaset.apps/customers-b59bf9968 1 1 1 14m replicaset.apps/orders-66b48ff4bb 1 1 1 14m replicaset.apps/reverseproxy-7977b6bd7f 1 1 1 14mI.e. the Reverse Proxy LoadBalancer service is available on the external IP address 172.18.255.1 (external as understood by the sample cluster) on TCP port 80 (standard HTTP), whereas the microservice endpoints are only available cluster-internally via ClusterIP services. And for each component there is a pod running as mandated by the deployments configuration by way of replica sets (of course I could scale up the number of pods to avoid a Single Point of Failure, but that’s beyond the scope of this post).
Query
And querying these sample services on the external IP address of the reverseproxy LoadBalancer service as listed above yields as follows:$ curl 172.18.255.1/api/customers/ "customers handled here" $ curl 172.18.255.1/api/orders/ "orders handled here" $ curl --head --silent 172.18.255.1/api/orders/ | grep Server Server: nginx/1.19.6So far so good: I can reach both endpoints, and both are available below the same IP address to which I could resolve a common domain. If I had created individual LoadBalancer services for each endpoint I would have ended up with separate IP addresses instead. And the last line indicates that it is indeed Nginx which had been handling these requests.
Downsides
Easy as this sample might be, it has some severe drawbacks:- for each new endpoint to add, I have to manually edit the Nginx config accordingly
- likewise, for each new feature to add, I have to manually edit the Nginx config accordingly, e.g. for access control, TLS/SSL termination / SSL offloading, …
- each such edit has the potential for completely hosing my reverse proxy configuration if I make a mistake, resulting in service disruptions
- and even further, how would I handle this if several disparate groups all want to use my reverse proxy, each for their own projects hosted in a common Kubernetes cluster? Would I grant them all full access?
Solution
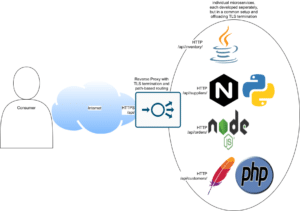
Instead, it is far more convenient to consolidate all this functionality into a common tool:- providing an interface for adding new endpoints, specifying both the domain and the path which should be served
- providing an interface to add additional features, e.g. for access control or TLS/SSL termination / SSL offloading
- collecting all configuration directives into a combined reverse proxy configuration
- while maintaining some degree of separation so that disparate groups can each work individually without affecting each other all too much when configuring the service
Such a setup might then be visualized like this:
Ingress Controllers
Ingress Controllers pick up the Ingress resources that will be fed into a Kubernetes cluster and combine those into a consolidated view about which routes will be allowed to pass from outside the Kubernetes cluster to services running inside the cluster and in what way. All Ingress Controller implementations should fulfill the basic reference specification, and in principle any number of Ingress Controller implementations can be deployed in a cluster, allowing to select the one that suits best individually per service and/or set a common default. There is a wide array of implementations available. And some of those which are currently rather popular will be handled in more detail in follow-up blog posts. This blog post here, on the other hand, was supposed to cover the general picture and the basic concepts, explaining the What and the Why of Ingress Controllers, and is thus just coming to an end now.Ingress Controller implementations covered in future posts
- ingress-nginx, an Nginx-based Ingress Controller that is a safe and one of the most popular choices when you need a simple solution
- Traefik, an Edge Router for publishing services that is not based on one of the common reverse proxy solutions and that is not limited to handling Kubernetes
- Istio Ingress, an Envoy-based solution integrated into the Istio Service Mesh